My talk from the 2019 AWS Summit in Berlin. I was talking about how we adapted our applications to running solely on Spot instances. Apart from the great cost saving effect, we've seen a great improvement in the resiliency of all our workloads.
-
Kubernetes and Spot Instances
-
Dealing with a catastrophe
AWS was preparing customers in us-east-1 for hurricane Florence and it remind me a bit of all the disastreous scenarios you can encounter when using AWS (and how you can mitigate them 100% better than if you we're running servers on-premise)
Scenario 1: hardware failure
One of the main advantages of cloud infra for me is not worrying about physical infrastructure at all. I recall a talk at an internal Rocket Internet Summit a few years ago. Some engineers had a 30 min talk how they found a bottleneck network link between their redis instances, affecting them for weeks. It felt crazy to spending time running around a datacenter instead of building ... products.
In general AWS will swap out any bad underlying hosts or disks without you knowing (I assume it's some sort of robot arms today). You will see a few practical implications though:
- EC2
- Run everything in ASGs.
You'll be used to instances being terminated and with a bit of work you won't recognize the difference between scaling down after peak and a unhealthy instance being terminated.
One pattern I see underused is running your single EC2 instances in an ASG as well, with min/max set to 1. In case it gets terminated, the ASG will spin up a replacement without manual action. In the case that you mutate the server state predictably (e.g. capistrano deployments), you can also make AMI snapshots to make it completely seamless. - RDS
- For production workloads, Multi-AZ is expensive, but also a must-have. In our experience you will see errors for up to 20 seconds. Careful that 90% of default connection pool configs in database client libs can't handle a DNS change afterfailover (1, 2). After fixing these issues across all our apps and frameworks, we feel comfortable enough to trigger failovers during live operations.
- Elasticache
- Same as for RDS, double check your redis client library if it can handle the failover gracefully. AWS allows you to trigger a manual failover at anytime
Scenario 2: AZ failure
In the Well-archited framework whitepapers, you'll find a lot of talking about availability zones. In the interface, AWS does a great job from giving an impression you have automatic datacenter redundancy, but you still need to be aware of how it all works. The first effect you might notice is that you will start accuring inter-AZ data transfer charges and I often see this as a source of frustration with EC2.
It's hard to detect an AZ failure in real time and there is no reliable API telling you which services in which AZ are not working properly. Some issues also manifest as connectivity issues between specific AZs. For that reason, we took a more manual emergency rulebook approach, which would allow the on-call engineer to follow steps to recover in case of a prolonged outage:
- Modifying auto-scaling policies to exclude the AZ we think is misbehaving
- Drain and decomission all instances already running within that AZ
- Manual failover all Multi-AZ RDS databases where the master is in the affected AZ
- Same manual failover for Elasticache clusters
One tough test for us was stateful cluster-forming applications, like Akka. Its default cluster formation heartbeats expect your instances to run within a single physical datacenter and cross-DC network jitter completely throws it off. By using the kubernetes API as a source of truth (etcd seems to be much more capable of handling cross AZ quorum maintenance) we were able to implement a very reliable split brain resolver handling the connectivity failures I mentioned above.
Scenario 3: Regional failure
We're not netflix, yet :)
-
Vizualizace CPU a RAM v Kubernetes clusteru
Mám několik týmů, které mají kontejnery ve sdíleném Kubernetes clusteru. Máme už takový pravidelný cyklus, že nám vylezou náklady nahoru a pak týmy týden poháníme ať zmenšují a šetří. Chvíli je klid (a lacino), a po pár týdnech začnou requesty na CPU a RAM zas bujet. Ostatně to samé máme s falešnýma alertama v monitoringu, ale o tom jindy.
Abych si ušetřil práci, a nakonec aby bylo pro každého na první pohled vidět, kdo je největší hříšník, jsem zbastlil malý skript, který vykreslí requesty pěkně v grafu. Vypadá to asi takhle:
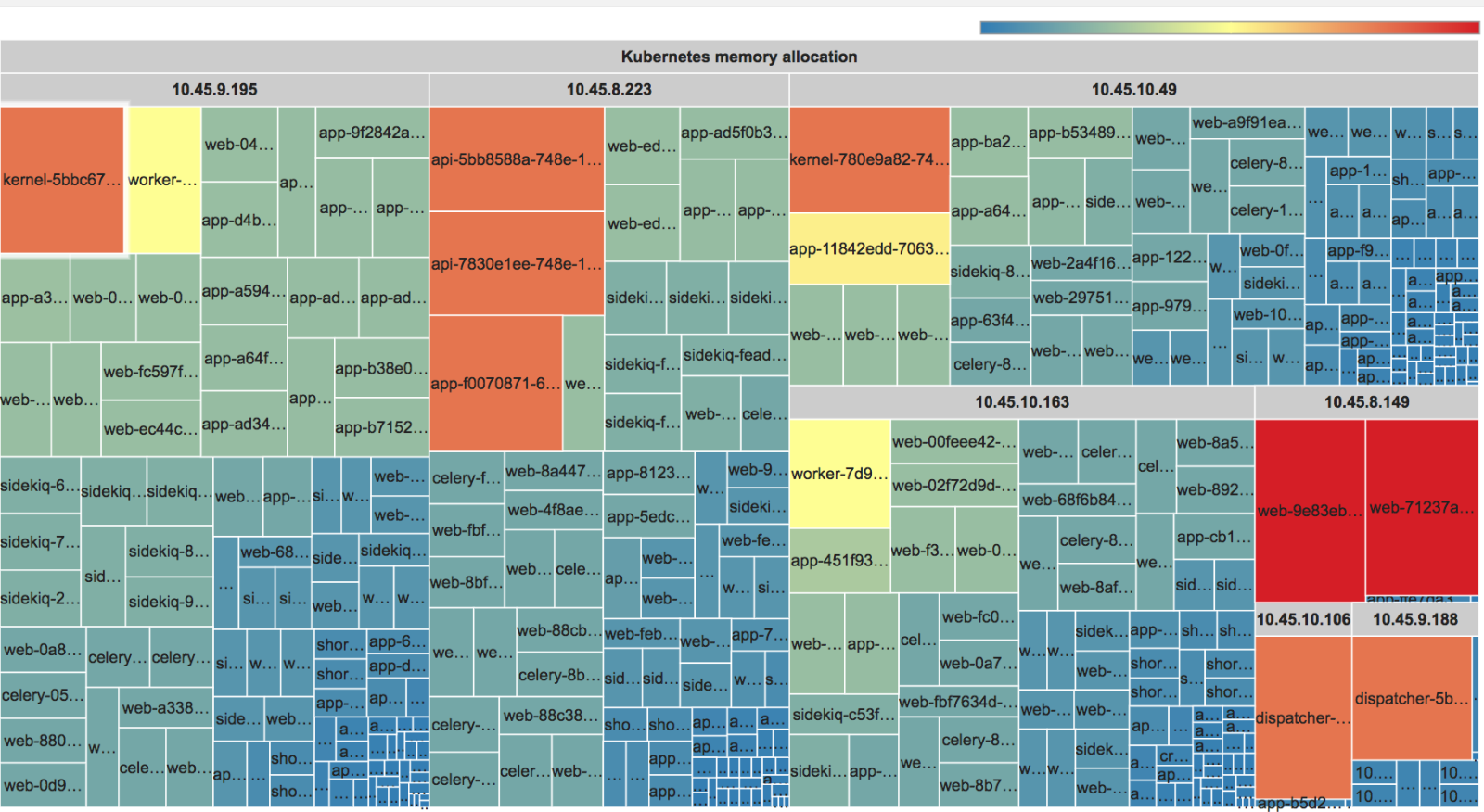
Zdrojáky jsem dal na github.com/vvondra/k8s-hostmap, je to malý Ruby server s dvěma šablonama pro CPU a RAM, který používá Treemap z Google Charts. Data si načte přes
kubectl proxy.Sleduju hlavně
requestsa ne limity, protože tlačíme aby je kontejnery měly blízko sebe a měli správně nastavené HPA. Request je kapacita, která je vždy rezervovaná a nemůže jí nikdy použít žádný jiný kontejner. Celkové využití RAM/CPU sledujeme spíš na autoscaleru clusteru, o tom třeba příště. -
Overengineering?
Poslední rok jsem propadl Ruby a jiným hipsterovinám a dokončil jsem tak první kolo životní cesty programátora. Všechno krátký, výstižný, žádné extra vrstvy. Pro jeden hobby projekt jsem zkusil zpracovat pokus ARESu o otevřená data a natáhnout seznam všech IČ v ČR. ARES šel cestou nejmenšího odporu, a tak vás čeká 500MB zazipovaný tarball, ve kterém je milion XML souborů, jeden pro každé IČ. No a nakonec jsem místo elegantního Ruby skončil u staré známé Javy.
Skoro mě dojala ta elegance práce s IO, se kterým jsem se poprvé setkal na škole a divil jsem se, proč prostě nepřečíst soubor do stringu a hotovo. Nabufferovat soubor, dekomprimovat, přečíst tar headery, pak pěkne jeden po druhém přečíst každý soubor a zarazit se tam, kde končí. Hotovo a paměti potřeba, že bych to spustil na Raspberry PI.TarArchiveInputStream tarInput = new TarArchiveInputStream( new GzipCompressorInputStream( new BufferedInputStream( new FileInputStream(file) ) ) ); TarArchiveEntry currentEntry; while ((currentEntry = tarInput.getNextTarEntry()) != null) { AresOdpovedi result = unmarshaller.unmarshal( new XmlStreamReader(new BoundedInputStream(tarInput, currentEntry.getSize())) ); }