It was quite an honor to join Dagi and Filemon on CZ Podcast. This time around your cloud invoices and ways to trim them down.
Listen to the whole episode:




It was quite an honor to join Dagi and Filemon on CZ Podcast. This time around your cloud invoices and ways to trim them down.
Listen to the whole episode:
In a few recent posts I talked about challenges growing an engineering startup team. The first one was about the timing of new processes and what are the right hires for early stages of a startup. The more recent one was about keeping sight of your 1 year plan and not drowning in daily firefights.
They both talked about the what to focus on, but not about the how to achieve it. There is one soft-skill that stands out as the biggest helper in this regard. It is learning to communicate well.
We've had a great chat with folks from Scede about leading teams split across multiple continents and about the challenges of a hybrid setup.
Listen to the whole episode:
Postgres is my Swiss army knife for storage and can cover the traditional relational database usecases, extreme scaling, NoSQL use-cases, analytics and much more. It's a great stack to start with and only after a long period of time you will see if you actually need something more specialized.
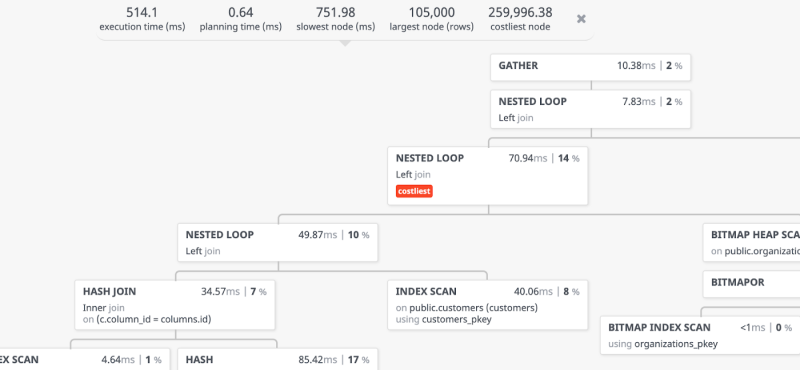
Here's a few helpful tips on the productboard engineering blog to make work with it even smoother, check it out.