Vizualizace CPU a RAM v Kubernetes clusteru
Mám několik týmů, které mají kontejnery ve sdíleném Kubernetes clusteru. Máme už takový pravidelný cyklus, že nám vylezou náklady nahoru a pak týmy týden poháníme ať zmenšují a šetří. Chvíli je klid (a lacino), a po pár týdnech začnou requesty na CPU a RAM zas bujet. Ostatně to samé máme s falešnýma alertama v monitoringu, ale o tom jindy.
Abych si ušetřil práci, a nakonec aby bylo pro každého na první pohled vidět, kdo je největší hříšník, jsem zbastlil malý skript, který vykreslí requesty pěkně v grafu. Vypadá to asi takhle:
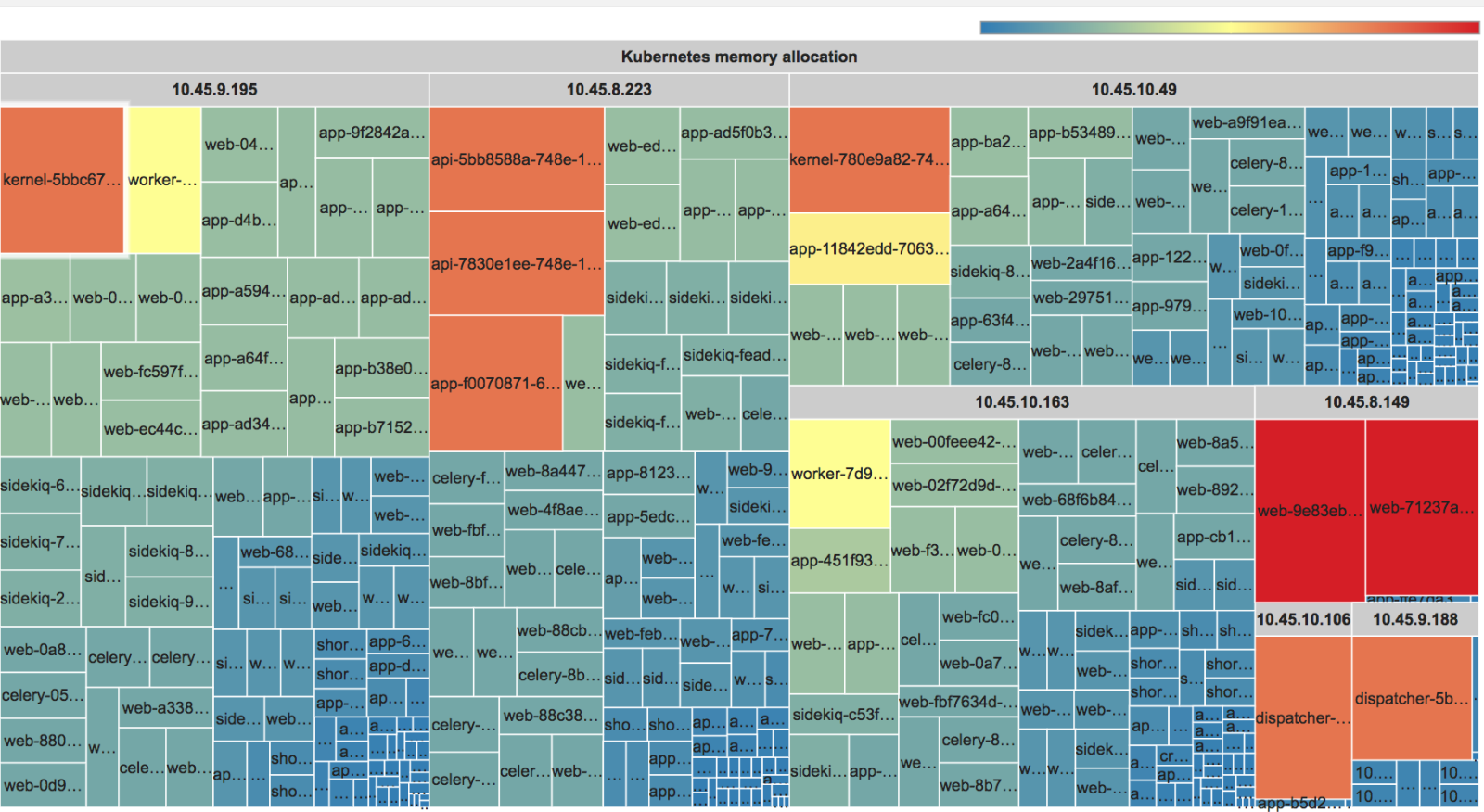
Zdrojáky jsem dal na github.com/vvondra/k8s-hostmap, je to malý Ruby server s dvěma šablonama pro CPU a RAM, který používá Treemap z Google Charts. Data si načte přes kubectl proxy.
Sleduju hlavně requests a ne limity, protože tlačíme aby je kontejnery měly blízko sebe a měli správně nastavené HPA. Request je kapacita, která je vždy rezervovaná a nemůže jí nikdy použít žádný jiný kontejner. Celkové využití RAM/CPU sledujeme spíš na autoscaleru clusteru, o tom třeba příště.